
Linux: Используем YAGF для удобного распознавания текста
YAGF — это графическая оболочка для cuneiform написанная Андреем Боровским:
Скачиваем исходный код YAGF:
symmetrica.net/cuneiform-linux/yagf-ru.html
Распаковываем. Для сборки необходимы qt и cmake, также понадобится libaspell-dev (я собирал в Ubuntu 9.10):
Теперь нам необходим cuneiform. Я пробовал собирать модифицированную версию 0.7.0 в которой есть возможность одновременно распознавать несколько языков, но она к сожалению не заработала, выдавая ошибку:
Я решил использовать обычную версию cuneiform, которая новее, чем на сайте YAGF. Получаем последние версии исходников с помощью Bazaar (в Ubuntu — пакет bzr):
Внимательно смотрим на результаты конфигурирования. Если видим сообщение о том, что ImageMagick++ не установлен — обязательно его устанавливаем (в Ubuntu — это пакет libmagick++-dev) иначе cuneiform сможет распознавать только bmp файлы:
Компилируем и устанавливаем:
Создаем символические ссылки для библиотек:
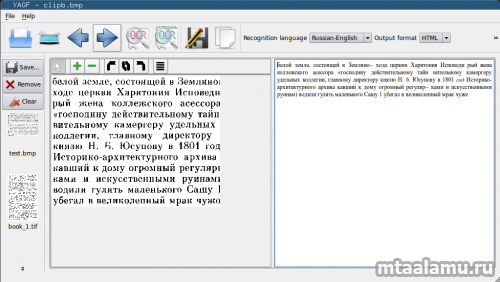
Запускаем и проверяем YAGF:
Скачиваем исходный код YAGF:
symmetrica.net/cuneiform-linux/yagf-ru.html
Распаковываем. Для сборки необходимы qt и cmake, также понадобится libaspell-dev (я собирал в Ubuntu 9.10):
cmake ./
make
sudo make installТеперь нам необходим cuneiform. Я пробовал собирать модифицированную версию 0.7.0 в которой есть возможность одновременно распознавать несколько языков, но она к сожалению не заработала, выдавая ошибку:
Cuneiform for Linux 0.7.0 (multilang)
*** glibc detected *** cuneiform: double free or corruption (!prev): 0x09f7b1c0 ***
======= Backtrace: =========
/lib/tls/i686/cmov/libc.so.6[0x60e1ff1]
/lib/tls/i686/cmov/libc.so.6[0x60e36f2]
/lib/tls/i686/cmov/libc.so.6(cfree+0x6d)[0x60e67cd]
/lib/tls/i686/cmov/libc.so.6(fclose+0x14a)[0x60d250a]
/usr/local/lib/librfrmt.so(RFRMT_Formatter+0x2b9)[0xbe5245]
/usr/local/lib/libpuma.so[0xb914ad]
/usr/local/lib/libpuma.so(PUMA_XFinalRecognition+0xdf)[0xb93a7b]
cuneiform[0x804afa3]
/lib/tls/i686/cmov/libc.so.6(__libc_start_main+0xe6)[0x608db56]
cuneiform[0x804a391]Я решил использовать обычную версию cuneiform, которая новее, чем на сайте YAGF. Получаем последние версии исходников с помощью Bazaar (в Ubuntu — пакет bzr):
bzr branch lp:cuneiform-linux
cd ./cuneiform-linux
mkdir builddir
cd builddir
cmake ./Внимательно смотрим на результаты конфигурирования. Если видим сообщение о том, что ImageMagick++ не установлен — обязательно его устанавливаем (в Ubuntu — это пакет libmagick++-dev) иначе cuneiform сможет распознавать только bmp файлы:
-- checking for module 'ImageMagick++'
-- package 'ImageMagick++' not foundКомпилируем и устанавливаем:
make
sudo make installСоздаем символические ссылки для библиотек:
ln -s /usr/local/lib/* /usr/lib/Запускаем и проверяем YAGF:
Комментарии (6)
RSS свернуть / развернутьahmetzyanov_d
yababay
durman
www.cuneiform.ru
Движок сейчас открыт и работает в консоли
YAGF — оболочка к нему
Sergei_T
www.opennet.ru/opennews/art.shtml?num=6608
yababay
Markony
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.