
Удобное распознавание текста в Linux
Несмотря на то, что в Linux вполне себе существуют командные утилиты для распознавания текста (gocr, cuneiform, tesseract) мне нехватало удобного интерфейса чтобы хоть как-то заменить Fine Reader, пока не нашел GTK утилиту ocrfeeder.
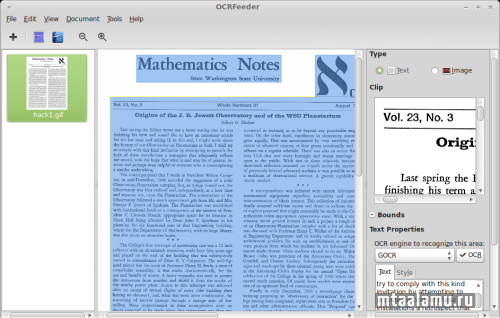
Утиль позволяет самому размечать область распознавания (может и автоматически, но не очень хорошо это делает), распознавать несколько страниц, экспортировать в опенофисовский формат, в PDF и т.п.
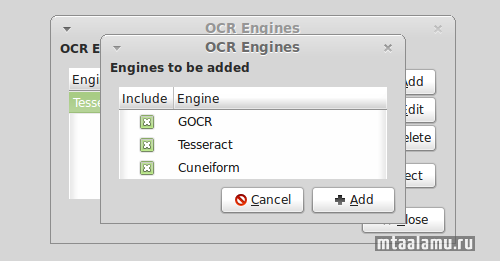
Утилита сама находит поддерживаемые OCR движки, можно подправить аргументы командной строки (чтобы, например, выбрать язык), можно самому сделать несколько вариантов выбора OCR движков с разными параметрами.
Утиль позволяет самому размечать область распознавания (может и автоматически, но не очень хорошо это делает), распознавать несколько страниц, экспортировать в опенофисовский формат, в PDF и т.п.
Утилита сама находит поддерживаемые OCR движки, можно подправить аргументы командной строки (чтобы, например, выбрать язык), можно самому сделать несколько вариантов выбора OCR движков с разными параметрами.
- —
- 28 мая 2013, 20:50
Комментарии (2)
RSS свернуть / развернутьyababay
Sergei_T
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.