
Jabber-бот на базе Яндекса
Некоторое время назад написал я программу-бота, которой можно управлять через XMPP-протокол (Jabber). Были у нее кое-какие-недостатки, из которых главный — требование запущенного на том же хосте Jabber-сервера.
Оценив ситуацию свежим взглядом решил, что держать свой сервер вовсе необязательно: кругом полно бесплатных. Сначала «переселил» бота на GoogleTalk. Всё прекрасно, управлять можно и из браузера, и из любого IM-клиента с поддержкой Jabber. А вот с мобильного телефона нельзя. Ну нет у Google нормального клиента для сервиса GTalk. Ну что-ж, тогда Яндекс. У этих ребят мобильный клиент давно написан: им можно и почту посмотреть, и пообЧАТься. Кроме того, из браузера чат тоже можно вести.
Сам бот тоже поумнел. Теперь он не только выполняет простые bash-команды, но и интерпретирует синтаксические конструкции на языках Java/Groovy, а также… переключает телевизионные каналы (да, такая вот Jabber-«лентяйка» для телевизора ).
).
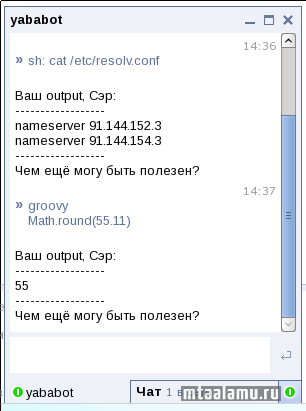
От злоумышленников бот защищен тем, что признает только команды, переданные с определенного аккаунта: чтобы управлять им, нужно сначала захватить мою учетную запись на Яндексе.
( Читать дальше )
Оценив ситуацию свежим взглядом решил, что держать свой сервер вовсе необязательно: кругом полно бесплатных. Сначала «переселил» бота на GoogleTalk. Всё прекрасно, управлять можно и из браузера, и из любого IM-клиента с поддержкой Jabber. А вот с мобильного телефона нельзя. Ну нет у Google нормального клиента для сервиса GTalk. Ну что-ж, тогда Яндекс. У этих ребят мобильный клиент давно написан: им можно и почту посмотреть, и пообЧАТься. Кроме того, из браузера чат тоже можно вести.
Сам бот тоже поумнел. Теперь он не только выполняет простые bash-команды, но и интерпретирует синтаксические конструкции на языках Java/Groovy, а также… переключает телевизионные каналы (да, такая вот Jabber-«лентяйка» для телевизора
).От злоумышленников бот защищен тем, что признает только команды, переданные с определенного аккаунта: чтобы управлять им, нужно сначала захватить мою учетную запись на Яндексе.
( Читать дальше )
RSS-редактор для гика
Оказывается, найти в Интернете редактор RSS-лент не так-то и просто. Встречаются или платные варианты, или кривые, или под Windows. Оно и понятно: для большинства блогов и движков RSS-фиды генерируются автоматически, на основе топиков. И всё-таки иногда возникает потребность создавать rss-потоки в ручном или полуавтоматическом режиме.
Поскольку найти готовое решение не удалось, решил написать самостоятельно. Нашел Java-библиотеку для генерации RSS (старенькая, но вполне адекватная, легкая и простая). С GUI решил не связываться, а парсить из текстового файла, особым образом размеченного, например, на основе синтаксиса wiki или asciidoc. Обрабатывать текстовой файл решил с помощью Groovy-скрипта. И вдруг такая идея: а зачем два файла, если внутри Groovy-программ можно прекрасно размещать многострочные текстовые блоки? Получилось вот что:
( Читать дальше )
Поскольку найти готовое решение не удалось, решил написать самостоятельно. Нашел Java-библиотеку для генерации RSS (старенькая, но вполне адекватная, легкая и простая). С GUI решил не связываться, а парсить из текстового файла, особым образом размеченного, например, на основе синтаксиса wiki или asciidoc. Обрабатывать текстовой файл решил с помощью Groovy-скрипта. И вдруг такая идея: а зачем два файла, если внутри Groovy-программ можно прекрасно размещать многострочные текстовые блоки? Получилось вот что:
( Читать дальше )
- +4
- 20 мая 2011, 23:03
- 2
Импортировать 150 картинок в базу данных за 3 минуты
Недавно я писал про базу данных с картинками. Может показаться, что занесение в ее графическое поле изображений — утомительный ручной процесс. Однако на самом деле всё сделано за считанные минуты небольшим groovy-скриптом.
Напомню, что координаты объектов на Google-картах были известны. Используя сервис статических карт нужно было оснастить записи картинками. Вот как это сделано:
Задействованный здесь метод stream2stream() я уже публиковал на Мтааламу, но, чтобы далеко не лазить, приведу еще раз:
Во избежание злоупотреблений, Google выдает за определенный небольшой промежуток времени не более 50 карт, так что скрипт пришлось запускать 3 раза с небольшими (пара минут) интервалами.
Напомню, что координаты объектов на Google-картах были известны. Используя сервис статических карт нужно было оснастить записи картинками. Вот как это сделано:
db = Sql.newInstance('jdbc:hsqldb:file:/path/to/db', 'SA', '', 'org.hsqldb.jdbc.JDBCDriver')
query = 'update name_descr_latlon set "mapimg"=? where "id"=?'
db.eachRow('select "id", "latlon" from name_descr_latlon where not ("latlon" is null) and "mapimg" is null'){ row ->
println row.id
url = new URL("http://maps.google.com/staticmap?markers=${row.latlon}&zoom=14&size=420x340")
baos = new ByteArrayOutputStream()
stream2stream(url.openStream(), baos)
ba = baos.toByteArray()
db.execute(query, [ba, row.id])
}Задействованный здесь метод stream2stream() я уже публиковал на Мтааламу, но, чтобы далеко не лазить, приведу еще раз:
import java.nio.ByteBuffer;
import java.nio.channels.Channels;
import java.nio.channels.ReadableByteChannel;
import java.nio.channels.WritableByteChannel;
import groovy.sql.Sql
def stream2stream = {is, os ->
src = Channels.newChannel(is);
dest = Channels.newChannel(os);
buffer = ByteBuffer.allocateDirect(16 * 1024);
while (src.read(buffer) != -1) {
buffer.flip();
dest.write(buffer);
buffer.compact();
}
buffer.flip();
while (buffer.hasRemaining())dest.write(buffer);
}
Во избежание злоупотреблений, Google выдает за определенный небольшой промежуток времени не более 50 карт, так что скрипт пришлось запускать 3 раза с небольшими (пара минут) интервалами.
- +12
- 15 марта 2011, 10:45
- 4
Пакетное преобразование файлов ape и flac в mp3 на языке Groovy
Музыкальные форматы ape и flac позволяют слушать музыку без искажений. Это, конечно, хорошо, но не все мобильные устройства их умеют воспроизводить. Поэтому, как ни грустно, приходится преобразовывать в mp3. Лучше всего делать это на каком-нибудь «сервере», т.е. постоянно работающей машине, раздающей, например, Интернет по квартире. Ей всё равно делать нечего: работает себе на антресолях, не шумит, пусть хоть всю ночь молотит. Однако для этого нужен консольный скрипт.
Если нужно преобразовать файлы всего в одном каталоге, то выглядит такой скрипт просто:
Но простота эта обманчива. Можно споткнуться о пробелы, содержащиеся в именах файлов. Если же речь идет не о единственном каталоге, а о множестве, да еще и с неопределенной степенью вложенности — придется задйствовать команду find, да и прочие огороды городить. Задолбавшись это делать, я решил задачу на языке Groovy.
Скрипт сохраняется с именем типа /usr/bin/apeflac2mpg. Далее следует зайти в каталог, где много неконвертированных файлов, запустить
отключиться от квартирного шлюза и… ложиться спать. К утру, может и успеет преобразовать гигабайт flac-файлов в mp3
Если нужно преобразовать файлы всего в одном каталоге, то выглядит такой скрипт просто:
for i in `ls *.{flac,ape}` ; do ffmpeg -ab 256k -i "$i" "$i.mp3"; doneНо простота эта обманчива. Можно споткнуться о пробелы, содержащиеся в именах файлов. Если же речь идет не о единственном каталоге, а о множестве, да еще и с неопределенной степенью вложенности — придется задйствовать команду find, да и прочие огороды городить. Задолбавшись это делать, я решил задачу на языке Groovy.
#!/usr/bin/groovy
dir = new File('.')
dir.eachFileRecurse {
if(it.getName().endsWith('.flac') || it.getName().endsWith('.ape')){
println it.getName()
mp3Name = it.getAbsolutePath() + '.mp3'
n = it.getName().lastIndexOf('.')
ext = it.getName().substring(n)
tmp = File.createTempFile('music', ext, dir)
mp3 = File.createTempFile('music', '.mp3', dir)
tmp.deleteOnExit()
it.renameTo(tmp)
ffmpeg = "ffmpeg -y -ab 256k -i ${tmp.getName()} ${mp3.getName()}".split(/\s+/).execute()
ffmpeg.waitFor()
mp3.renameTo(new File(mp3Name))
}
}
Скрипт сохраняется с именем типа /usr/bin/apeflac2mpg. Далее следует зайти в каталог, где много неконвертированных файлов, запустить
screen apeflac2mpgотключиться от квартирного шлюза и… ложиться спать. К утру, может и успеет преобразовать гигабайт flac-файлов в mp3
- +4
- 22 января 2011, 16:26
- комментировать