Несколько лучше в SL4A обстоит дело с поддержкой скриптового языка lua, но тоже не блестяще (с 2010 года этот плагин не обновлялся и не стыкуется со свежей версией самого фреймворка). Но нет худа без добра. Ковыряясь с этим хозяйством я обнаружил, что lua очень похож на JS и освоить его быстро вполне себе можно. Есть даже фреймворк для lua-разработки прямо в мобильной среде — SigmaScript. Только вот возможности его, как мне показалось, весьма ограничены…
Среди массы проектов для программирования на lua под Android резко выделяется AndroLua. Автор этого довольно свежего проекта (код обновлялся 2 месяца назад) совершил как минимум два подвига. Во-первых, скомпилировал стандартный lua-движок в нативную андроидскую библиотеку, во-вторых, вкорячил в свое приложение еще и LuaJava — фреймворк для стыковки программ на lua и Java. Поскольку программы для Android как раз и работают в Java-среде (хотя и несколько специфической), это дает возможность обращаться практически ко всем возможностям ОС (точнее говоря API).
В AndroLua есть также возможность кодить не с экранной клавиатуры смартфона, а с нормальной, хардварной, подключенной к ПК. Это еще одна причина того, что я не стал делать ставку на SigmaScript, где такой возможности нет. Чтобы кодить в такой клиент-серверной среде нужно включить на мобильном устройстве режим отладки по сети, подключиться с ПК, пробросить порты, запустить на смартфоне AndroLua (она поднимает сервер-интерпретатор на порту 3333) и вводить команды прямо с консоли:
./adb connect 10.10.10.10
./adb forward tcp:3333 tcp:3333
lua interp.lua
О том, что обращаться к Java-API Android-устройства действительно удается, свидетельствует скриншот:
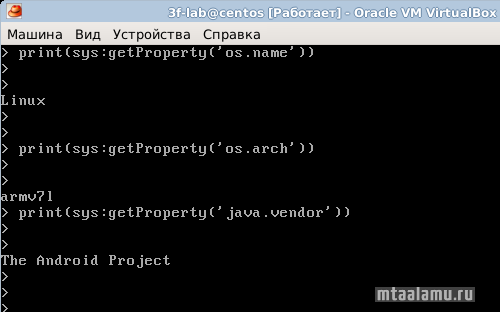 ]]>
]]> ]]>
]]>


 .]]>
.]]>